Publications
Some peer-reviewed publications. Check my Google scholar for the complete list.
2025
-
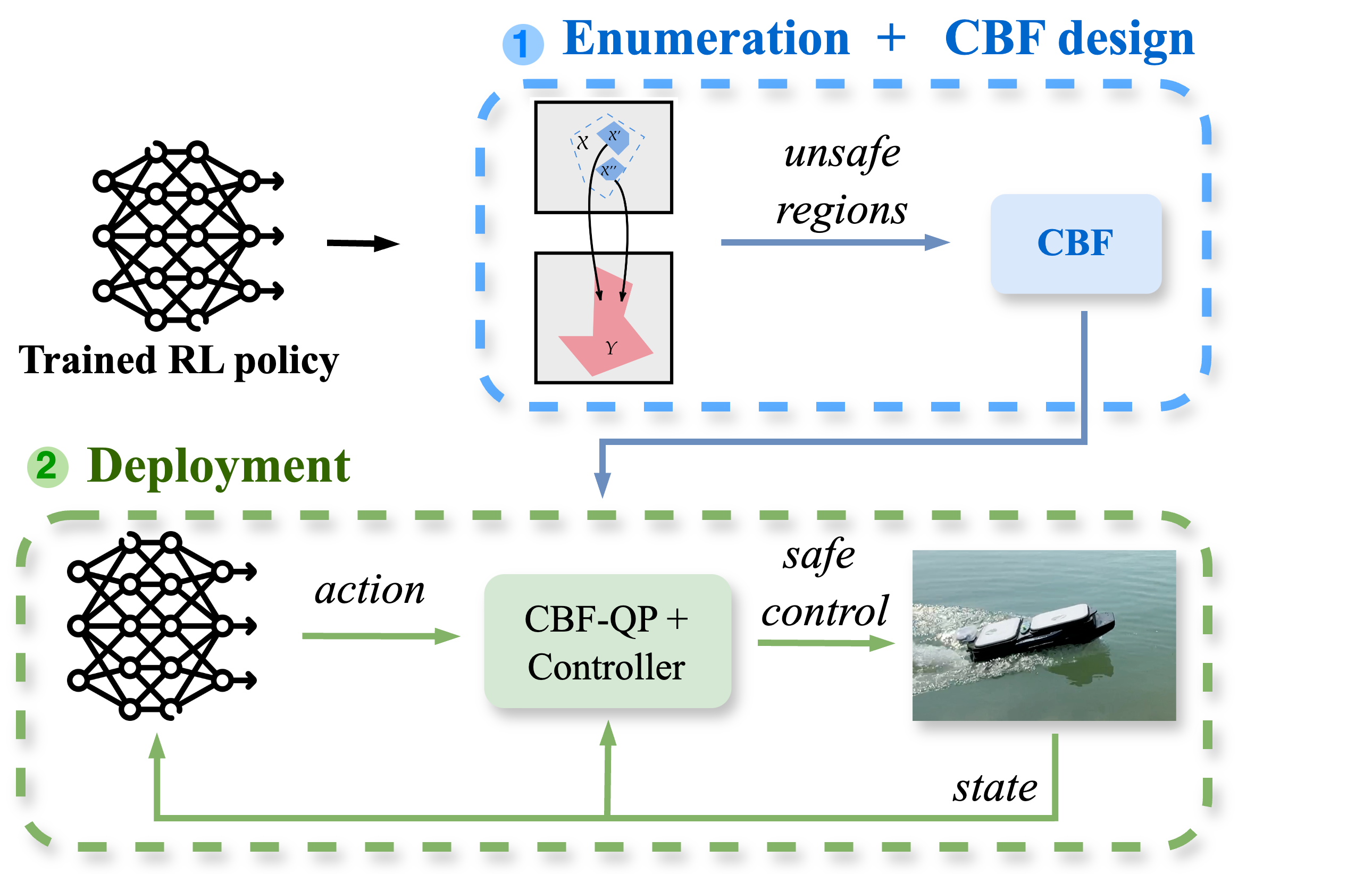 Designing Control Barrier Function via Probabilistic Enumeration for Safe Reinforcement Learning NavigationLuca Marzari, Francesco Trotti, Enrico Marchesini, and Alessandro FarinelliIEEE Robotics and Automation Letters (RAL), 2025
Designing Control Barrier Function via Probabilistic Enumeration for Safe Reinforcement Learning NavigationLuca Marzari, Francesco Trotti, Enrico Marchesini, and Alessandro FarinelliIEEE Robotics and Automation Letters (RAL), 2025Achieving safe autonomous navigation systems is critical for deploying robots in dynamic and uncertain real-world environments. In this paper, we propose a hierarchical control framework leveraging neural network verification techniques to design control barrier functions (CBFs) and policy correction mechanisms that ensure safe reinforcement learning navigation policies. Our approach relies on probabilistic enumeration to identify unsafe regions of operation, which are then used to construct a safe CBF-based control layer applicable to arbitrary policies. We validate our framework both in simulation and on a real robot, using a standard mobile robot benchmark and a highly dynamic aquatic environmental monitoring task. These experiments demonstrate the ability of the proposed solution to correct unsafe actions while preserving efficient navigation behavior. Our results show the promise of developing hierarchical verification-based systems to enable safe and robust navigation behaviors in complex scenarios.
@article{ralcbf, title = {Designing Control Barrier Function via Probabilistic Enumeration for Safe Reinforcement Learning Navigation}, author = {Marzari, Luca and Trotti, Francesco and Marchesini, Enrico and Farinelli, Alessandro}, journal = {IEEE Robotics and Automation Letters (RAL)}, pages = {9630-9637}, doi = {10.1109/LRA.2025.3596431}, year = {2025}, } -
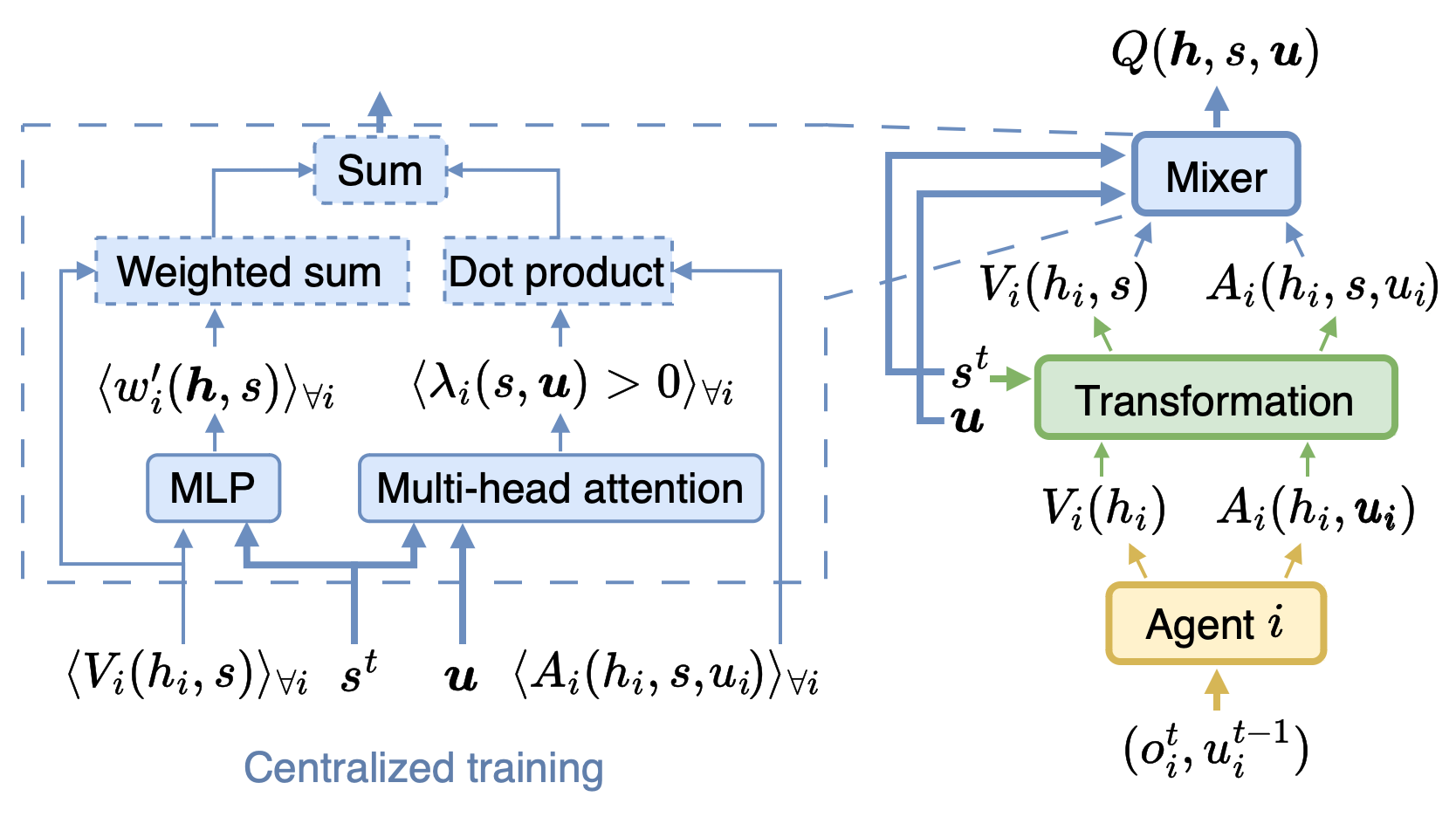 On Stateful Value Factorization in Multi-Agent Reinforcement LearningEnrico Marchesini, Andrea Baisero, Rupali Bhati, and Christopher AmatoIn (to appear) International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2025
On Stateful Value Factorization in Multi-Agent Reinforcement LearningEnrico Marchesini, Andrea Baisero, Rupali Bhati, and Christopher AmatoIn (to appear) International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2025Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information – making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods – reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.
@inproceedings{statefuligm, title = {On Stateful Value Factorization in Multi-Agent Reinforcement Learning}, author = {Marchesini, Enrico and Baisero, Andrea and Bhati, Rupali and Amato, Christopher}, booktitle = {(to appear) International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)}, year = {2025}, url = {https://arxiv.org/abs/2408.15381}, } -
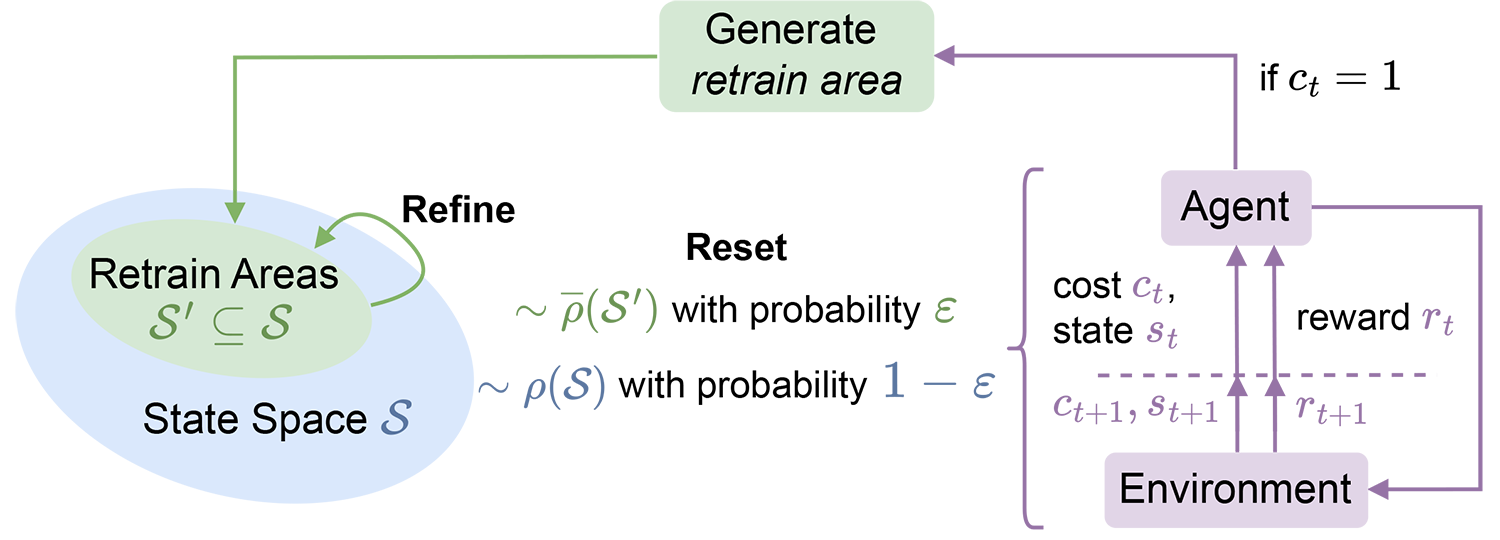 Improving Policy Optimization via ε-RetrainLuca Marzari, Changliu Liu, Priya Donti, and Enrico MarchesiniIn International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2025
Improving Policy Optimization via ε-RetrainLuca Marzari, Changliu Liu, Priya Donti, and Enrico MarchesiniIn International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2025We present ε-retrain, an exploration strategy designed to encourage a behavioral preference while optimizing policies with monotonic improvement guarantees. To this end, we introduce an iterative procedure for collecting retrain areas – parts of the state space where an agent did not follow the behavioral preference. Our method then switches between the typical uniform restart state distribution and the retrain areas using a decaying factor ε, allowing agents to retrain on situations where they violated the preference. Experiments over hundreds of seeds across locomotion, navigation, and power network tasks show that our method yields agents that exhibit significant performance and sample efficiency improvements. Moreover, we employ formal verification of neural networks to provably quantify the degree to which agents adhere to behavioral preferences.
@inproceedings{epsretrain, title = {Improving Policy Optimization via \epsilon-Retrain}, author = {Marzari, Luca and Liu, Changliu and Donti, Priya and Marchesini, Enrico}, booktitle = {International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)}, pages = {1464–1472}, isbn = {9798400714269}, year = {2025}, url = {https://arxiv.org/abs/2406.08315}, }



2024
- AAMASEntropy Seeking Constrained Multiagent Reinforcement LearningAyhan Alp Aydeniz, Enrico Marchesini, Christopher Amato, and Kagan TumerIn International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2024
Multiagent Reinforcement Learning (MARL) has been successfully applied to domains requiring close coordination among many agents. However, real-world tasks require safety specifications that are not generally considered by MARL algorithms. In this work, we introduce an Entropy Seeking Constrained (ESC) approach aiming to learn safe cooperative policies for multiagent systems. Unlike previous methods, ESC considers safety specifications while maximizing state-visitation entropy, addressing the exploration issues of constrained-based solutions.
@inproceedings{AAMAS2024_entrmarl, title = {Entropy Seeking Constrained Multiagent Reinforcement Learning}, author = {Aydeniz, Ayhan Alp and Marchesini, Enrico and Amato, Christopher and Tumer, Kagan}, booktitle = {International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)}, pages = {2141–2143}, isbn = {9798400704864}, year = {2024}, } -
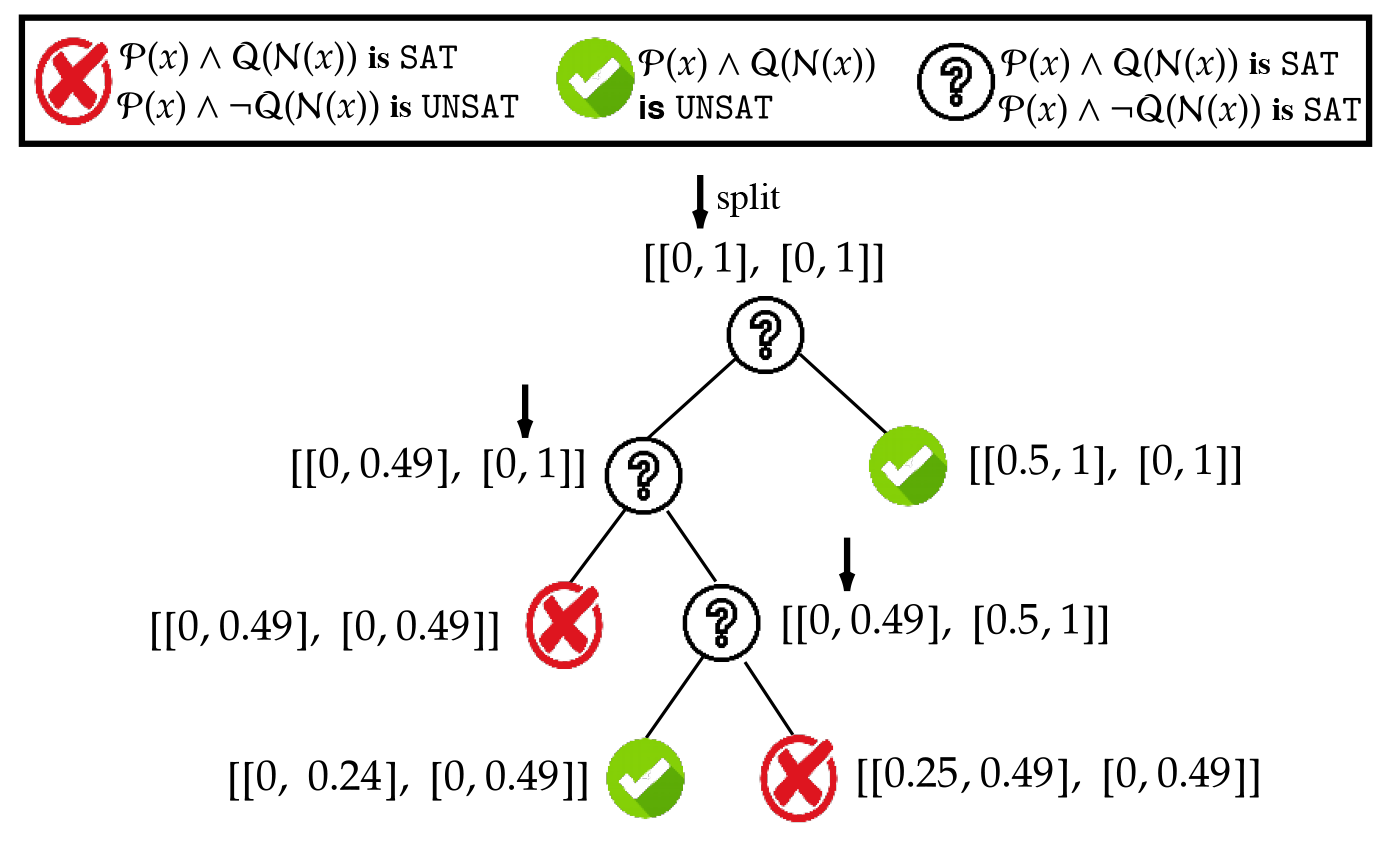 Enumerating Safe Regions in Deep Neural Networks with Provable Probabilistic GuaranteesLuca Marzari, Davide Corsi, Enrico Marchesini, Alessandro Farinelli, and 1 more authorIn AAAI Conference on Artificial Intelligence (AAAI), 2024
Enumerating Safe Regions in Deep Neural Networks with Provable Probabilistic GuaranteesLuca Marzari, Davide Corsi, Enrico Marchesini, Alessandro Farinelli, and 1 more authorIn AAAI Conference on Artificial Intelligence (AAAI), 2024Identifying safe areas is a key point to guarantee trust for systems that are based on Deep Neural Networks (DNNs). To this end, we introduce the AllDNN-Verification problem: given a safety property and a DNN, enumerate the set of all the regions of the property input domain which are safe, i.e., where the property does hold. Due to the #P-hardness of the problem, we propose an efficient approximation method called ε-ProVe. Our approach exploits a controllable underestimation of the output reachable sets obtained via statistical prediction of tolerance limits, and can provide a tight —with provable probabilistic guarantees— lower estimate of the safe areas. Our empirical evaluation on different standard benchmarks shows the scalability and effectiveness of our method, offering valuable insights for this new type of verification of DNNs.
@inproceedings{AAAI2024_probabfv, title = {Enumerating Safe Regions in Deep Neural Networks with Provable Probabilistic Guarantees}, author = {Marzari, Luca and Corsi, Davide and Marchesini, Enrico and Farinelli, Alessandro and Cicalese, Ferdinando}, booktitle = {AAAI Conference on Artificial Intelligence (AAAI)}, pages = {21387-21394}, doi = {10.1609/aaai.v38i19.30134}, year = {2024}, }

2023
-
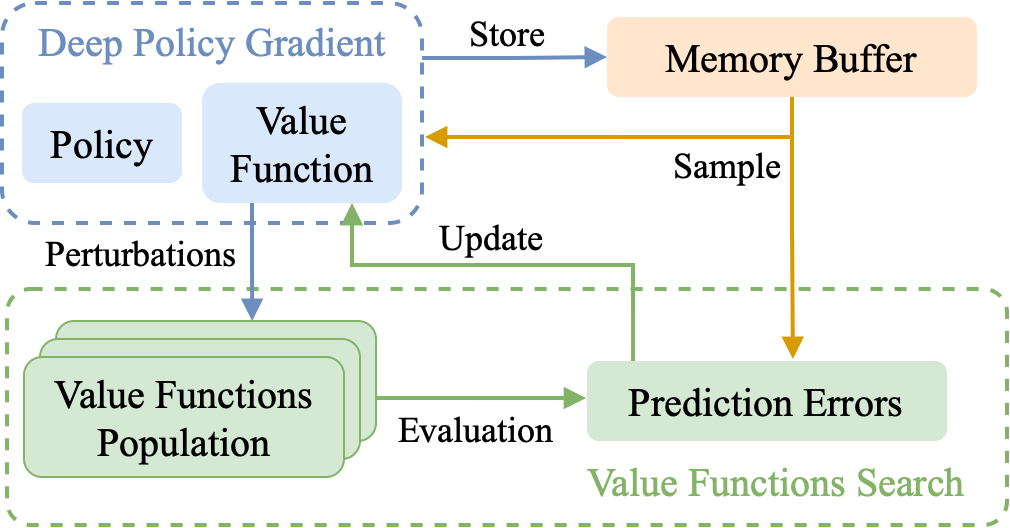 Improving Deep Policy Gradients via Value Function SearchEnrico Marchesini, and Christopher AmatoIn International Conference on Learning Representations (ICLR), 2023
Improving Deep Policy Gradients via Value Function SearchEnrico Marchesini, and Christopher AmatoIn International Conference on Learning Representations (ICLR), 2023Deep Policy Gradient (PG) algorithms employ value networks to drive the learning of parameterized policies and reduce the variance of the gradient estimates. However, value function approximation gets stuck in local optima and struggles to fit the actual return, limiting the variance reduction efficacy and leading policies to sub-optimal performance. In this paper, we focus on improving value approximation and analyzing the effects on Deep PG primitives such as value prediction, variance reduction, and correlation of gradient estimates with the true gradient. To this end, we introduce a Value Function Search that employs a population of perturbed value networks to search for a better approximation. Our framework does not require additional environment interactions, gradient computations, or ensembles, providing a computationally inexpensive approach to enhance the supervised learning task on which value networks train. Crucially, we show that improving Deep PG primitives results in improved sample efficiency and policies with higher returns using common continuous control benchmark domains.
@inproceedings{ICLR2023_vfs, title = {Improving Deep Policy Gradients via Value Function Search}, author = {Marchesini, Enrico and Amato, Christopher}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2023}, url = {https://openreview.net/forum?id=6qZC7pfenQm}, } -
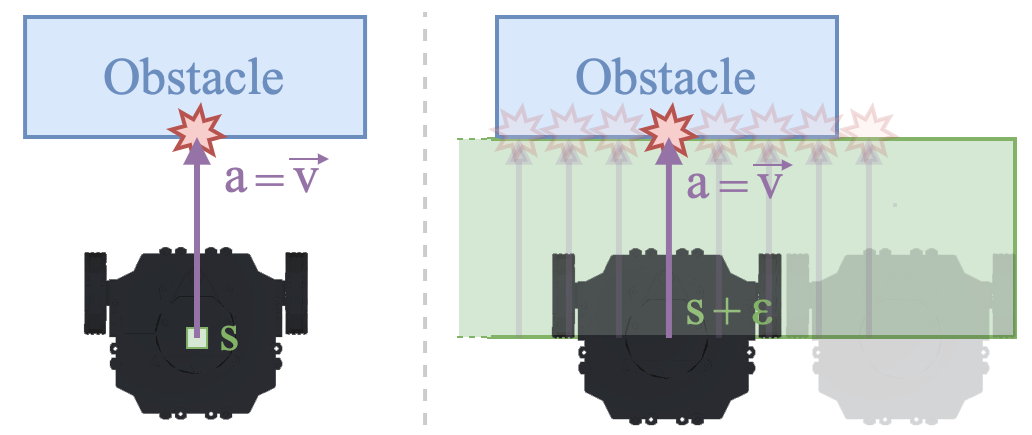 Safe Deep Reinforcement Learning by Verifying Task-Level PropertiesEnrico Marchesini, Luca Marzari, Alessandro Farinelli, and Christopher AmatoIn International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2023
Safe Deep Reinforcement Learning by Verifying Task-Level PropertiesEnrico Marchesini, Luca Marzari, Alessandro Farinelli, and Christopher AmatoIn International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2023Cost functions are commonly employed in Safe Deep Reinforcement Learning (DRL). However, the cost is typically encoded as an indicator function due to the difficulty of quantifying the risk of policy decisions in the state space. Such an encoding requires the agent to visit numerous unsafe states to learn a cost-value function to drive the learning process toward safety. Hence, increasing the number of unsafe interactions and decreasing sample efficiency. In this paper, we investigate an alternative approach that uses domain knowledge to quantify the risk in the proximity of such states by defining a violation metric. This metric is computed by verifying task-level properties, shaped as input-output conditions, and it is used as a penalty to bias the policy away from unsafe states without learning an additional value function. We investigate the benefits of using the violation metric in standard Safe DRL benchmarks and robotic mapless navigation tasks. The navigation experiments bridge the gap between Safe DRL and robotics, introducing a framework that allows rapid testing on real robots. Our experiments show that policies trained with the violation penalty achieve higher performance over Safe DRL baselines and significantly reduce the number of visited unsafe states.
@inproceedings{AAMAS2023_violationpenalty, title = {Safe Deep Reinforcement Learning by Verifying Task-Level Properties}, author = {Marchesini, Enrico and Marzari, Luca and Farinelli, Alessandro and Amato, Christopher}, booktitle = {International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)}, year = {2023}, } -
 Online Safety Property Collection and Refinement for Safe Deep Reinforcement Learning in Mapless NavigationLuca Marzari, Enrico Marchesini, and Alessandro FarinelliIn International Conference on Robotics and Automation (ICRA), 2023
Online Safety Property Collection and Refinement for Safe Deep Reinforcement Learning in Mapless NavigationLuca Marzari, Enrico Marchesini, and Alessandro FarinelliIn International Conference on Robotics and Automation (ICRA), 2023Safety is essential for deploying Deep Reinforcement Learning (DRL) algorithms in real-world scenarios.Recently, verification approaches have been proposed to allow quantifying the number of violations of a DRL policy over input-output relationships, called properties. However, such properties are hard-coded and require task-level knowledge, making their application intractable in challenging safety-critical tasks. To this end, we introduce the Collection and Refinement of Online Properties (CROP) framework to design properties at training time. CROP employs a cost signal to identify unsafe interactions and use them to shape safety properties. Hence, we propose a refinement strategy to combine properties that model similar unsafe interactions.Our evaluation compares the benefits of computing the number of violations using standard hard-coded properties and the ones generated with CROP. We evaluate our approach in several robotic mapless navigation tasks and demonstrate that the violation metric computed with CROP allows higher returns and lower violations over previous Safe DRL approaches.
@inproceedings{ICRA2023_crop, title = {Online Safety Property Collection and Refinement for Safe Deep Reinforcement Learning in Mapless Navigation}, author = {Marzari, Luca and Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {International Conference on Robotics and Automation (ICRA)}, year = {2023}, }



2022
-
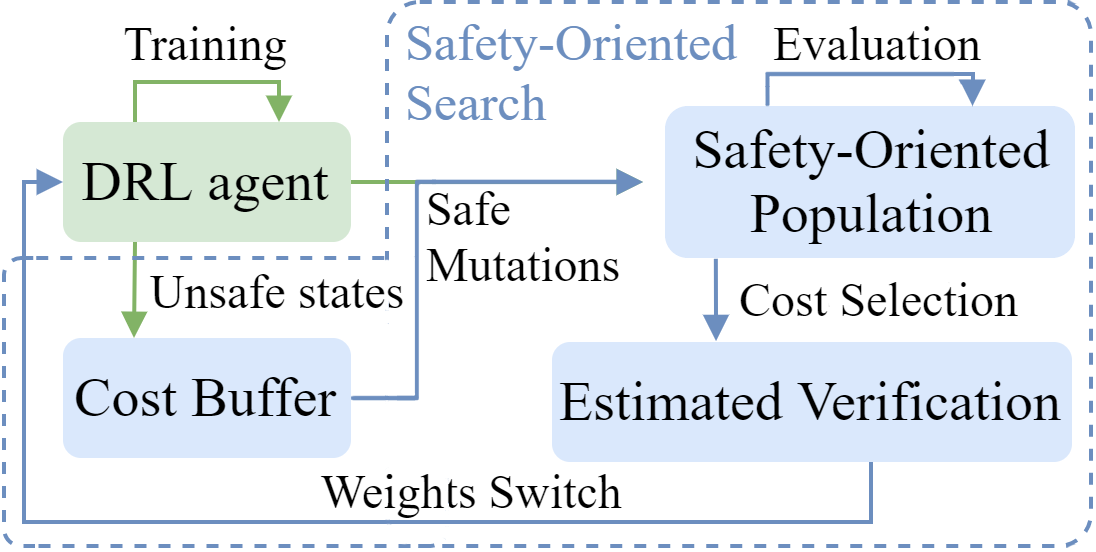 Exploring Safer Behaviors for Deep Reinforcement LearningEnrico Marchesini, Davide Corsi, and Alessandro FarinelliAAAI Conference on Artificial Intelligence (AAAI), 2022
Exploring Safer Behaviors for Deep Reinforcement LearningEnrico Marchesini, Davide Corsi, and Alessandro FarinelliAAAI Conference on Artificial Intelligence (AAAI), 2022We consider Reinforcement Learning (RL) problems where an agent attempts to maximize a reward signal while minimizing a cost function that models unsafe behaviors. Such formalization is addressed in the literature using constrained optimization on the cost, limiting the exploration and leading to a significant trade-off between cost and reward. In contrast, we propose a Safety-Oriented Search that complements Deep RL algorithms to bias the policy toward safety within an evolutionary cost optimization. We leverage evolutionary exploration benefits to design a novel concept of safe mutations that use visited unsafe states to explore safer actions. We further characterize the behaviors of the policies over desired specifics with a sample-based bound estimation, which makes prior verification analysis tractable in the training loop. Hence, driving the learning process towards safer regions of the policy space. Empirical evidence on the Safety Gym benchmark shows that we successfully avoid drawbacks on the return while improving the safety of the policy.
@article{AAAI2022, title = {Exploring Safer Behaviors for Deep Reinforcement Learning}, author = {Marchesini, Enrico and Corsi, Davide and Farinelli, Alessandro}, journal = {AAAI Conference on Artificial Intelligence (AAAI)}, pages = {7701-7709}, doi = {10.1609/aaai.v36i7.20737}, year = {2022}, } - GECCOSafety-Informed Mutations for Evolutionary Deep Reinforcement LearningEnrico Marchesini, and Christopher AmatoIn Genetic and Evolutionary Computation Conference Companion (GECCO), 2022
Evolutionary Algorithms have been combined with Deep Reinforcement Learning (DRL) to address the limitations of the two approaches while leveraging their benefits. In this paper, we discuss objective-informed mutations to bias the evolutionary population toward exploring the desired objective. We focus on Safe DRL domains to show how these mutations exploit visited unsafe states to search for safer actions. Empirical evidence on a 12 degrees of freedom locomotion benchmark and a practical navigation task, confirm that we improve the safety of the policy while maintaining comparable return with the original DRL algorithm.
@inproceedings{GECCO2022, title = {Safety-Informed Mutations for Evolutionary Deep Reinforcement Learning}, author = {Marchesini, Enrico and Amato, Christopher}, booktitle = {Genetic and Evolutionary Computation Conference Companion (GECCO)}, pages = {1966–1970}, doi = {10.1145/3520304.3533980}, year = {2022}, } -
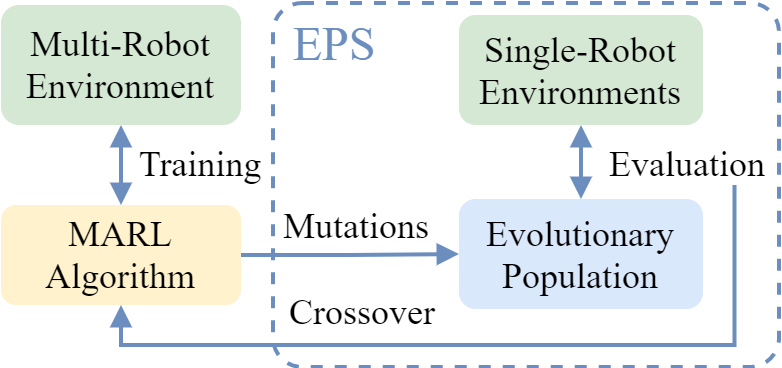 Enhancing Deep Reinforcement Learning Approaches for Multi-Robot Navigation via Single-Robot Evolutionary Policy SearchEnrico Marchesini, and Alessandro FarinelliIn International Conference on Robotics and Automation (ICRA), 2022
Enhancing Deep Reinforcement Learning Approaches for Multi-Robot Navigation via Single-Robot Evolutionary Policy SearchEnrico Marchesini, and Alessandro FarinelliIn International Conference on Robotics and Automation (ICRA), 2022Recent Multi-Agent Deep Reinforcement Learning approaches factorize a global action-value to address non-stationarity and favor cooperation. These methods, however, hinder exploration by introducing constraints (e.g., additive value-decomposition) to guarantee the factorization. Our goal is to enhance exploration and improve sample efficiency of multi-robot mapless navigation by incorporating a periodical Evolutionary Policy Search (EPS). In detail, the multi-agent training “specializes” the robots’ policies to learn the collision avoidance skills that are mandatory for the task. Concurrently, in this work we propose the use of Evolutionary Algorithms to explore different regions of the policy space in an environment with only a single robot. The idea is that core navigation skills, originated by the multi-robot policies using mutation operators, improve faster in the single-robot EPS. Hence, policy parameters can be injected into the multi-robot setting using crossovers, leading to improved performance and sample efficiency. Experiments in tasks with up to 12 robots confirm the beneficial transfer of navigation skills from the EPS to the multi-robot setting, improving the performance of prior methods.
@inproceedings{ICRA2022, title = {Enhancing Deep Reinforcement Learning Approaches for Multi-Robot Navigation via Single-Robot Evolutionary Policy Search}, author = {Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {International Conference on Robotics and Automation (ICRA)}, pages = {5525-5531}, doi = {10.1109/ICRA46639.2022.9812341}, year = {2022}, } - PhD ThesisEnhancing Exploration and Safety in Deep Reinforcement LearningEnrico MarchesiniIn Ph.D. Thesis, 2022
A Deep Reinforcement Learning (DRL) agent tries to learn a policy maximizing a long-term objective by trials and errors in large state spaces (Sutton and Barto, 2018). However, this learning paradigm requires a non-trivial amount of interactions in the environment to achieve good performance. Moreover, critical applications, such as robotics (OpenAI et al., 2019), typically involve safety criteria to consider while designing novel DRL solutions. Hence, devising safe learning approaches with efficient exploration is crucial to avoid getting stuck in local optima, failing to learn properly, or causing damages to the surrounding environment (Garcıa and Fernández, 2015). This thesis focuses on developing Deep Reinforcement Learning algorithms to foster efficient exploration and safer behaviors in simulation and real domains of interest, ranging from robotics to multi-agent systems. To this end, we rely both on standard benchmarks, such as SafetyGym (Ray et al., 2019), and robotic tasks widely adopted in the literature (e.g., manipulation (Gu et al., 2017), navigation (Tai et al., 2017)). This variety of problems is crucial to assess the statistical significance of our empirical studies and the generalization skills of our approaches (Henderson et al., 2018). We initially benchmark the sample efficiency versus performance trade-off between value-based and policy-gradient algorithms. This part highlights the benefits of us- ing non-standard simulation environments (i.e., Unity (Juliani et al., 2018)), which also facilitates the development of further optimization for DRL. We also discuss the limitations of standard evaluation metrics (e.g., return) in characterizing the actual behaviors of a policy, proposing the use of Formal Verification (FV) (Liu et al., 2019) as a practical methodology to evaluate behaviors over desired specifications. The second part introduces Evolutionary Algorithms (EAs) (Fogel, 2006) as a gradient- free complimentary optimization strategy. In detail, we combine population-based and gradient-based DRL to diversify exploration and improve performance both in single and multi-agent applications. For the latter, we discuss how prior Multi-Agent (Deep) Reinforcement Learning (MARL) approaches hinder exploration (Rashid et al., 2018), proposing an architecture that favors cooperation without affecting exploration.
@inproceedings{PhDThesis, title = {Enhancing Exploration and Safety in Deep Reinforcement Learning}, author = {Marchesini, Enrico}, booktitle = {Ph.D. Thesis}, year = {2022}, }


2021
-
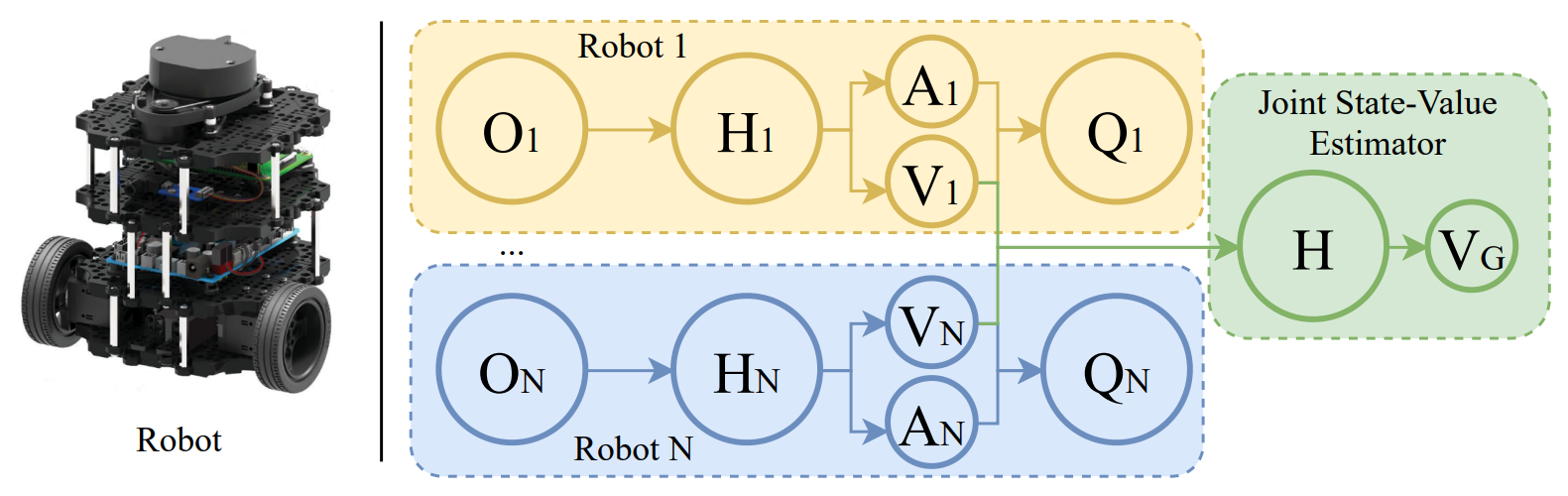 Centralizing State-Values in Dueling Networks for Multi-Robot Reinforcement Learning Mapless NavigationEnrico Marchesini, and Alessandro FarinelliIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021
Centralizing State-Values in Dueling Networks for Multi-Robot Reinforcement Learning Mapless NavigationEnrico Marchesini, and Alessandro FarinelliIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021We study the problem of multi-robot mapless navigation in the popular Centralized Training and Decentralized Execution (CTDE) paradigm. This problem is challenging when each robot considers its path without explicitly sharing observations with other robots and can lead to non-stationary issues in Deep Reinforcement Learning (DRL). The typical CTDE algorithm factorizes the joint action-value function into individual ones, to favor cooperation and achieve decentralized execution. Such factorization involves constraints (e.g., monotonicity) that limit the emergence of novel behaviors in an individual as each agent is trained starting from a joint action-value. In contrast, we propose a novel architecture for CTDE that uses a centralized state-value network to compute a joint state-value, which is used to inject global state information in the value-based updates of the agents. Consequently, each model computes its gradient update for the weights, considering the overall state of the environment. Our idea follows the insights of Dueling Networks as a separate estimation of the joint state-value has both the advantage of improving sample efficiency, while providing each robot information whether the global state is (or is not) valuable. Experiments in a robotic navigation task with 2 4, and 8 robots, confirm the superior performance of our approach over prior CTDE methods (e.g., VDN, QMIX).
@inproceedings{IROS2021_marl, title = {Centralizing State-Values in Dueling Networks for Multi-Robot Reinforcement Learning Mapless Navigation}, author = {Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {4583-4588}, doi = {10.1109/IROS51168.2021.9636349}, year = {2021}, } -
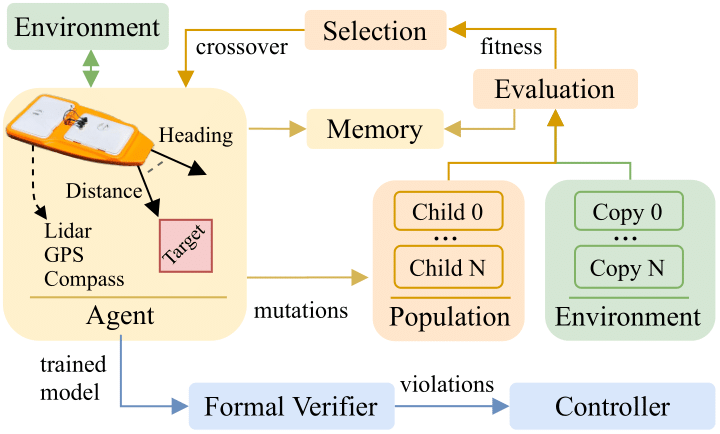 Benchmarking Safe Deep Reinforcement Learning in Aquatic NavigationEnrico Marchesini, Davide Corsi, and Alessandro FarinelliIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021
Benchmarking Safe Deep Reinforcement Learning in Aquatic NavigationEnrico Marchesini, Davide Corsi, and Alessandro FarinelliIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021We propose a novel benchmark environment for Safe Reinforcement Learning focusing on aquatic navigation Aquatic navigation is an extremely challenging task due to the non-stationary environment and the uncertainties of the robotic platform, hence it is crucial to consider the safety aspect of the problem, by analyzing the behavior of the trained network to avoid dangerous situations (e.g., collisions). To this end, we consider a value-based and policy-gradient Deep Reinforcement Learning (DRL) and we propose a crossover-based strategy that combines gradient-based and gradient-free DRL to improve sample-efficiency. Moreover, we propose a verification strategy based on interval analysis that checks the behavior of the trained models over a set of desired properties. Our results show that the crossover-based training outperforms prior DRL approaches, while our verification allows us to quantify the number of configurations that violate the behaviors that are described by the properties. Crucially, this will serve as a benchmark for future research in this domain of applications.
@inproceedings{IROS2021_intcatch, title = {Benchmarking Safe Deep Reinforcement Learning in Aquatic Navigation}, author = {Marchesini, Enrico and Corsi, Davide and Farinelli, Alessandro}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {5590-5595}, doi = {10.1109/IROS51168.2021.9635925}, year = {2021}, } -
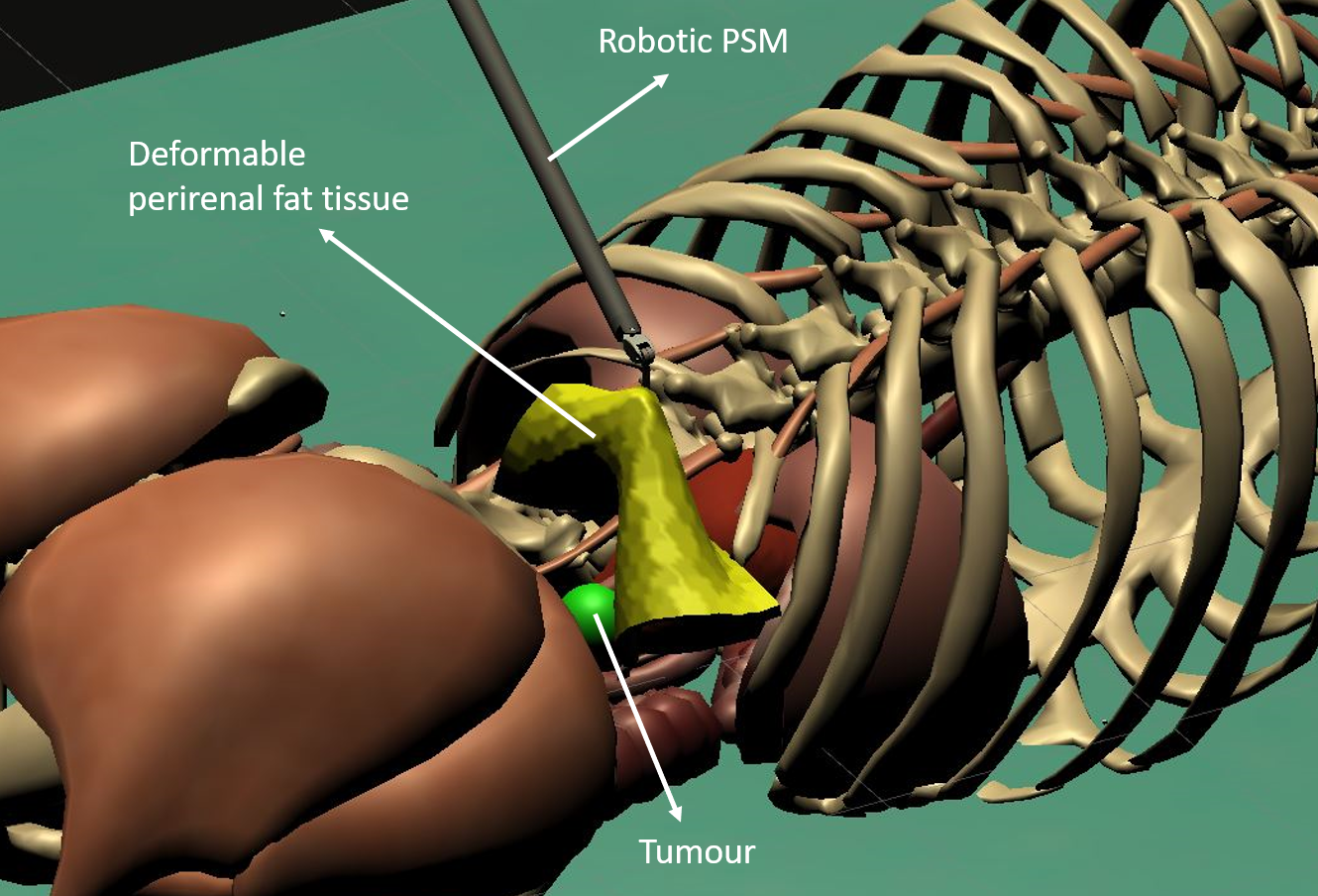 Safe Reinforcement Learning using Formal Verification for Tissue Retraction in Autonomous Robotic-Assisted SurgeryAmeya Pore, Davide Corsi, Enrico Marchesini, Diego Dall’Alba, and 3 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021
Safe Reinforcement Learning using Formal Verification for Tissue Retraction in Autonomous Robotic-Assisted SurgeryAmeya Pore, Davide Corsi, Enrico Marchesini, Diego Dall’Alba, and 3 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021Deep Reinforcement Learning (DRL) is a viable solution for automating repetitive surgical subtasks due to its ability to learn complex behaviours in a dynamic environment. This task automation could lead to reduced surgeon’s cognitive workload, increased precision in critical aspects of the surgery, and fewer patient-related complications. However, current DRL methods do not guarantee any safety criteria as they maximise cumulative rewards without considering the risks associated with the actions performed. Due to this limitation, the application of DRL in the safety-critical paradigm of robot-assisted Minimally Invasive Surgery (MIS) has been constrained. In this work, we introduce a Safe-DRL framework that incorporates safety constraints for the automation of surgical subtasks via DRL training. We validate our approach in a virtual scene that replicates a tissue retraction task commonly occurring in multiple phases of an MIS. Furthermore, to evaluate the safe behaviour of the robotic arms, we formulate a formal verification tool for DRL methods that provides the probability of unsafe configurations. Our results indicate that a formal analysis guarantees safety with high confidence such that the robotic instruments operate within the safe workspace and avoid hazardous interaction with other anatomical structures.
@inproceedings{IROS2021_surgery, title = {Safe Reinforcement Learning using Formal Verification for Tissue Retraction in Autonomous Robotic-Assisted Surgery}, author = {Pore, Ameya and Corsi, Davide and Marchesini, Enrico and Dall’Alba, Diego and Casals, Alicia and Farinelli, Alessandro and Fiorini, Paolo}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {4025-4031}, doi = {10.1109/IROS51168.2021.9636175}, year = {2021}, } -
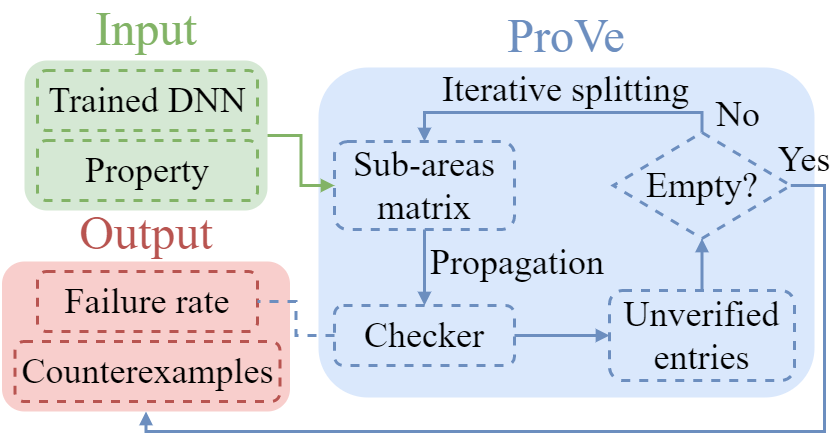 Formal verification of neural networks for safety-critical tasks in deep reinforcement learningDavide Corsi, Enrico Marchesini, and Alessandro FarinelliIn Conference on Uncertainty in Artificial Intelligence (UAI), 2021
Formal verification of neural networks for safety-critical tasks in deep reinforcement learningDavide Corsi, Enrico Marchesini, and Alessandro FarinelliIn Conference on Uncertainty in Artificial Intelligence (UAI), 2021In the last years, neural networks achieved groundbreaking successes in a wide variety of applications. However, for safety critical tasks, such as robotics and healthcare, it is necessary to provide some specific guarantees before the deployment in a real world context. Even in these scenarios, where high cost equipment and human safety are involved, the evaluation of the models is usually performed with the standard metrics (i.e., cumulative reward or success rate). In this paper, we introduce a novel metric for the evaluation of models in safety critical tasks, the violation rate. We build our work upon the concept of formal verification for neural networks, providing a new formulation for the safety properties that aims to ensure that the agent always makes rational decisions. To perform this evaluation, we present ProVe (Property Verifier), a novel approach based on the interval algebra, designed for the analysis of our novel behavioral properties. We apply our method to different domains (i.e., mapless navigation for mobile robots, trajectory generation for manipulators, and the standard ACAS benchmark). Results show that the violation rate computed by ProVe provides a good evaluation for the safety of trained models.
@inproceedings{UAI2021, title = {Formal verification of neural networks for safety-critical tasks in deep reinforcement learning}, author = {Corsi, Davide and Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)}, pages = {333-343}, year = {2021}, } - ICLRGenetic Soft Updates for Policy Evolution in Deep Reinforcement LearningEnrico Marchesini, Davide Corsi, and Alessandro FarinelliIn International Conference on Learning Representations (ICLR), 2021
The combination of Evolutionary Algorithms (EAs) and Deep Reinforcement Learning (DRL) has been recently proposed to merge the benefits of both solutions. Existing mixed approaches, however, have been successfully applied only to actor-critic methods and present significant overhead. We address these issues by introducing a novel mixed framework that exploits a periodical genetic evaluation to soft update the weights of a DRL agent. The resulting approach is applicable with any DRL method and, in a worst-case scenario, it does not exhibit detrimental behaviours. Experiments in robotic applications and continuous control benchmarks demonstrate the versatility of our approach that significantly outperforms prior DRL, EAs, and mixed approaches. Finally, we employ formal verification to confirm the policy improvement, mitigating the inefficient exploration and hyper-parameter sensitivity of DRL.ment, mitigating the inefficient exploration and hyper-parameter sensitivity of DRL.
@inproceedings{ICLR2021, title = {Genetic Soft Updates for Policy Evolution in Deep Reinforcement Learning}, author = {Marchesini, Enrico and Corsi, Davide and Farinelli, Alessandro}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2021}, url = {https://openreview.net/forum?id=TGFO0DbD_pk}, }




2020
-
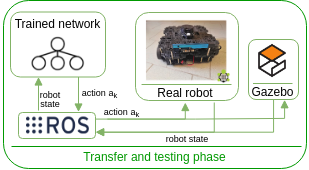 Discrete Deep Reinforcement Learning for Mapless NavigationEnrico Marchesini, and Alessandro FarinelliIn IEEE International Conference on Robotics and Automation (ICRA), 2020
Discrete Deep Reinforcement Learning for Mapless NavigationEnrico Marchesini, and Alessandro FarinelliIn IEEE International Conference on Robotics and Automation (ICRA), 2020Our goal is to investigate whether discrete state space algorithms are a viable solution to continuous alternatives for mapless navigation. To this end we present an approach based on Double Deep Q-Network and employ parallel asynchronous training and a multi-batch Priority Experience Replay to reduce the training time. Experiments show that our method trains faster and outperforms both the continuous Deep Deterministic Policy Gradient and Proximal Policy Optimization algorithms. Moreover, we train the models in a custom environment built on the recent Unity learning toolkit and show that they can be exported on the TurtleBot3 simulator and to the real robot without further training. Overall our optimized method is 40% faster compared to the original discrete algorithm. This setting significantly reduces the training times with respect to the continuous algorithms, maintaining a similar level of success rate hence being a viable alternative for mapless navigation.
@inproceedings{ICRA2020, title = {Discrete Deep Reinforcement Learning for Mapless Navigation}, author = {Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, pages = {10688-10694}, doi = {10.1109/ICRA40945.2020.9196739}, year = {2020}, } -
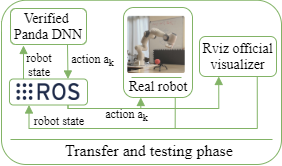 Formal Verification for Safe Deep Reinforcement Learning in Trajectory GenerationDavide Corsi, Enrico Marchesini, and Alessandro FarinelliIn IEEE International Conference on Robotic Computing (IRC), 2020
Formal Verification for Safe Deep Reinforcement Learning in Trajectory GenerationDavide Corsi, Enrico Marchesini, and Alessandro FarinelliIn IEEE International Conference on Robotic Computing (IRC), 2020We consider the problem of Safe Deep Reinforcement Learning (DRL) using formal verification in a trajectory generation task. In more detail, we propose an approach to verify whether a trained model can generate trajectories that are guaranteed to meet safety properties (e.g., operate in a limited work-space). We show that our verification approach based on interval analysis, provably guarantees whether a model meets pre-specified safety properties and it returns the input values that cause a violation of such properties. Furthermore, we show that an optimized DRL approach (i.e., using scaling discount factor and a mixed exploration policy based on a directional controller) can reach the target with millimeter precision while reducing the set of inputs that cause safety violations. Crucially, in our experiments, the number of undesirable inputs is so low that they can be directly removed with a simple controller.
@inproceedings{IRC2020, title = {Formal Verification for Safe Deep Reinforcement Learning in Trajectory Generation}, author = {Corsi, Davide and Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {IEEE International Conference on Robotic Computing (IRC)}, pages = {352-359}, doi = {10.1109/IRC.2020.00062}, year = {2020}, } - AAMASGenetic Deep Reinforcement Learning for Mapless NavigationEnrico Marchesini, and Alessandro FarinelliIn 19th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2020
We consider Deep Reinforcement Learning (DRL) approaches to devise mapless navigation strategies for mobile platforms. We propose a Genetic Deep Reinforcement Learning (GDRL) method that combines Genetic Algorithms (GA) with discrete and continuous action space DRL approaches. The goal of GDRL is to reduce the sensitivity of DRL approaches to their hyper-parameter tuning and to provide robust exploration strategies. We evaluate GDRL in combination with Rainbow and Proximal Policy Optimization (PPO) in two navigation scenarios: i) a wheeled robot avoiding obstacles in an indoor environment and ii) a water drone that must reach a predefined location in presence of waves. Our empirical evaluation demonstrates that GDRL outperforms state-of-the-art DRL and GA methods as well as a previous hybrid approach.
@inproceedings{AAMAS2020, title = {Genetic Deep Reinforcement Learning for Mapless Navigation}, author = {Marchesini, Enrico and Farinelli, Alessandro}, booktitle = {19th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)}, pages = {1919–1921}, isbn = {9781450375184}, year = {2020}, }

